
Operation-Level Security for the Swarm Era
What fraud rings and coordinated behavior teach us about adversary swarms

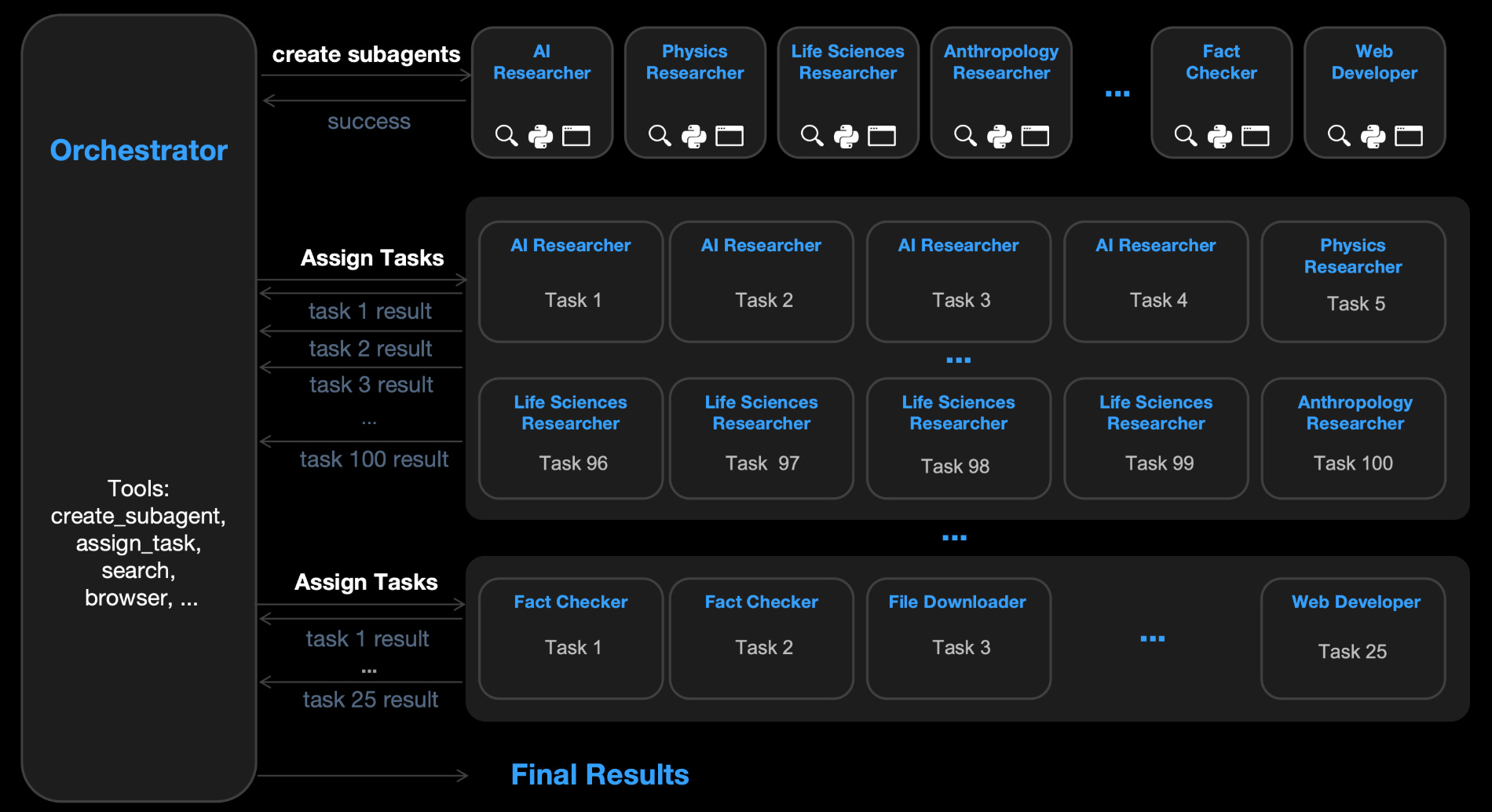
With its release of Kimi K2.5, Moonshot also shipped an Agent Swarm mode. That mode can decompose a single request into parallel sub-tasks executed by a coordinated set of dynamically instantiated agents. Public write-ups describe swarms on the order of ~100 sub-agents, with parallel tool use at large scale.
Swarming itself isn’t the innovation here. Multi-agent orchestration has been possible for a while. What is changing here is packaging and defaultability. Swarming is moving from an engineering pattern into a product feature. With that, the diffusion curve shifts. Swarms become a trivial option in the toolbox for developers, analysts, and attackers.
That shift matters because most enterprise monitoring for agentic systems is still anchored at the micro level. Teams are instrumenting for single exchanges (prompt/response, tool call/result). Some teams are graduating to single-agent trajectories (sequences across time). Swarming pushes us toward a third object that most orgs are not yet addressing: the operation.
An operation is a distributed meta-task pursued through many agents, sessions, channels, and identities, often intentionally unlinked. In the adversarial case, de-linking is a key part of the strategy. That should force a corresponding change in detection and defense: from detecting adversarial prompts or malicious agents to detecting coordinated campaigns.
What is new
Orchestrated campaigns are not a new thing. Botnets, fraud rings, scripted recon, and commodity automation are not new. Even within the AI space, many teams already use multi-agent patterns: planners, routers, tool specialists, verifier loops, parallel retrieval, and so on.
Orchestration itself is not what makes this beta release significant. Instead it is the combination of:
Lower coordination cost. Swarm-style systems reduce the human overhead of decomposing work and managing threads.
Adaptive coordination. Instead of running a fixed script at scale, systems can adjust tactics based on intermediate results.
Normalized parallel tool use. The default assumption shifts from one agent taking steps to many concurrent threads exploring and executing.
Kimi K2.5 is a marker that this bundle is reaching mainstream.
Adversarial orchestration is already here
The likely trajectory of this seems clear. Offensive automation is being productized.
HexStrike has drawn attention as an open-source attempt to bind LLM-driven agents to a broad tool catalog and execute end-to-end security workflows through an orchestration layer. It can apparently support autonomous use of 100+ security tools and seems likely to compress the time from vulnerability disclosure to practical exploitation
We are observing the same pattern that played out with earlier red-team tooling: capabilities built for defenders become dual-use, and then get pulled into attacker workflows. What’s different this time around is that AI-assisted orchestration compresses iteration cycles, increases flexibility across targets and channels, and reduces the skill needed to coordinate complex, multi-threaded operations. That undermines defenses that assume stable identity and a coherent session.
Monitoring gap: from input-output, to trajectories, to operations
Today, most enterprise AI telemetry is optimized for debugging and governance at the individual input-output exchange: log prompts, log tool calls, redact sensitive fields, keep enough context to reproduce a failure. That better than nothing, but it leaves a lot uncovered.
Trajectory monitoring has become the next frontier for agent security, but even here it mostly remains a single-agent story. This can help us examine whether agents took unsafe sequences of actions or failed to follow a policy over time. These are genuine concerns, but again they cover only part of the challenge.
Swarming introduces a new failure mode: each individual trajectory can be policy-compliant and benign-looking, while the aggregate operation is not. This is the same gap that fraud and platform integrity teams have lived with for years. You don’t catch a coordinated campaign because one event looks off. You catch it because problematic activity becomes clusterable at the group/operation level.
Example: coordinated support abuse leading to account takeover
Let’s consider a scenario faced by many enterprise security teams: support-assisted account compromise. Imagine a large SaaS provider with a support organization that can perform account recovery actions, ownership changes, SSO troubleshooting, and emergency access resets. The company has controls: verification steps, scripts, escalation procedures, audit logs. The support team is trained. The workflows look secure on the surface.
When leveraging orchestration, an adversary isn’t aiming for a single successful attack, but instead a distributed exploration of the support surface area:
Multiple independent-looking requests across regions and time zones.
Each request tests a different edge case in the support workflow: policy ambiguity, exception handling, escalation routing, identity verification friction.
Some requests fail and terminate. Others succeed partially (extracting non-sensitive but operationally useful information).
The operation converges on the lowest-friction path. The campaign discovered which combination of conditions, timing, and routing increased success probability.
Nothing here requires a single agent to behave obviously maliciously. Each interaction can be framed as a legitimate customer problem: an SSO misconfiguration, a locked account, an urgent access request for business continuity, a request to update contact details after a reorg. Individual tickets can look like normal traffic.
What changes in the swarm setting is the economics and the search strategy. The adversary can run many parallel experiments, learn which support branches are brittle, then concentrate effort where success is most likely. The attack is not one thrust, but campaign-level adaptation.
From the defender’s perspective, this is a hard case: it is not really a model-level jailbreak problem; rather a coordination problem interacting with enterprise processes.
Why per-agent monitoring fails here
If you instrument the support channel as independent interactions, your logs will show exactly what you expect to see in normal operations: some failed verifications, some escalations, some denied requests, some approved. You may even have transcripts, agent assist logs, and tool-call traces if AI is in the loop.
The issue is that the signal is not localized. It is relational:
The timing pattern looks like phased exploration, not a single incident.
The request content shares a goal structure even when surface phrasing differs.
The escalation paths converge on a subset of workflows that are consistently easier.
The operation stops or pivots as soon as friction increases in one channel, shifting to another.
A mature SOC has seen similar challenges in how fraud rings, credential stuffing waves, and abuse campaigns operate. But most agent-security telemetry pipelines are not built to express that structure as a first-class object.
Lessons from fraud and platform integrity
Fraud detection and platform integrity work because they treat coordination as a statistical object rather than a narrative one. They build systems that form and update hypotheses about linked activities, including in cases where the attacker(s) aim to prevent explicit linkage.
It’s worth starting by pointing to some constraints in the enterprise context. In a large org, the telemetry relevant to the support an account takeover scenario can be fragmented across contact center software, ticketing systems, identity providers, CRM records, email gateways, WAF/CDN logs, application telemetry, and possibly third-party call outsourcing. Privacy rules can constrain what you can retain from transcripts or identity documents. In sum, organizational boundaries can constrain correlation even when it is technically possible.
The goal can’t be perfect attribution. It is a minimum viable operation layer that works at an acceptable layer given the signals that an org has available.
In practice, three categories of correlation tend to be most important:
Sequence correlation. Even when identities rotate, coordinated operations often share a characteristic path through workflows: which support categories they select, which escalations they trigger, which error states they probe, and how they behave when denied. This is why trajectory thinking can help. But it must be generalized from an agent trajectory to a workflow trajectory across actors.
Temporal structure. Operations have phases: exploration, convergence, exploitation, consolidation. The time signature can be more revealing than any single artifact. Enterprises routinely log timestamps; they rarely model phase transitions as part of detection.
Cross-channel adaptation. The strongest signal that you are observing a centrally optimized operation is synchronized change: a wave stops, shifts, or reroutes in response to friction. That is difficult to fake perfectly because it reflects global objective pursuit.
Infrastructure fingerprints (e.g., device signatures) can be strong signals, but they are unevenly available in enterprise environments. Semantic clustering can be powerful, but it must be governed carefully. The point is not to obsess about any one feature, but to build a system that can gather together what you can reliably observe.
How monitoring and logging change when operations become a focal point
This leads to two questions: what can be implemented with existing telemetry and operational constraints, and what can be standardized into controls that remain effective at scale across heterogeneous environments.
The core shift is to log for correlation rather than for debugging. That sounds straightforward, but it forces disciplined engineering choices. You need stable identifiers not only for users and sessions, but for workflow states, action categories, and high-risk transitions. You need event schemas that stay consistent across channels. You need to represent sequences and relationships (e.g., request A followed denial B followed escalation C) rather than treating events as isolated entities. And you need enough fingerprinting and context to make clustering feasible without creating an ungovernable privacy and retention problem.
This is where the thinking purely in terms of agent security can become too narrow. In the support-driven account takeover scenario, the primary weakness is rarely agent autonomy in the abstract. It is the enterprise process surface itself, and the telemetry required to detect coordinated probing of that surface across identities, channels, and time.
In that sense, the emerging technical requirement is operation-level observability and response: the ability to form and act on hypotheses about coordinated campaigns, even when individual interactions look ordinary in isolation.
Operation hypotheses as first-class objects
One way to make this concrete is to treat operation detection as an explicit layer in the telemetry stack. The job of that layer is to take the streams you already have, align them across channels, and continuously surface clusters of activity that are likely coordinated.
In an enterprise setting, the inputs are typically available even if they live in different systems: support tickets and chat sessions, authentication and recovery events from the identity provider, administrative changes to accounts, CRM or customer-record updates, and audit events tied to high-risk support actions. These events need to be normalized into a shared schema so they can be analyzed together. A feature layer then extracts correlation signals that persist even when identities rotate: workflow and sequence signatures (how requests move through support and recovery), temporal structure (bursts, phase shifts, repeated probing), intent similarity where content retention is permitted, and coarse technical fingerprints where the environment provides them. A clustering layer groups events into candidate operations and assigns each cluster a confidence score along with the evidence supporting the linkage. A response layer applies proportionate controls to higher-confidence operations: step-up verification on sensitive flows, throttling at the operation level, temporary constraints on the most abusable recovery actions, routing to specialist queues, and targeted instrumentation to improve visibility while the operation is active.
This approach treats an operation as a computed object that evolves as new events arrive. The cluster is updated continuously, and the score shifts as evidence accumulates or dissipates. That makes the output usable in real time, not only in post-incident reconstruction.
It also forces a set of tradeoffs. High-confidence clusters can justify stronger friction, while lower-confidence clusters call for lighter interventions and additional measurement. The controls need to be graded and reversible because uncertainty is structural in adversarial settings, especially when the attacker is investing in de-linking identities. The practical goal is to raise the marginal cost of coordinated exploration and exploitation without imposing broad, persistent friction on legitimate users.
Urgency because swarms amplify an existing blind spot
Support-based account takeover and coordinated probing already exist. There is no doubt about that. The question is whether agent swarms change the situation enough to force new investment.
I think they do because they increase two attacker advantages:
Parallel exploration at low marginal cost. Attackers can test many workflow edges simultaneously and quickly learn where human processes are brittle.
Adaptive coordination across channels. A swarm can maintain a coherent objective while expressing it through different personas, different timing, and different phrasing, reducing the telltale repetition that older automation often produced.
That does not mean every attacker will suddenly run high quality swarms. But it does mean that the baseline cost of coordination drops, and the distribution of attacker sophistication shifts. The result is not necessarily more spectacular attacks; it is more frequent, more adaptive operations that stress the seams of enterprise process controls.
How enterprises should respond
The first step is conceptual: stop treating monitoring as an attribute of agents alone. Operations require us to also look at the system and organization as objects for monitoring.
From there, other changes are more concrete. Prioritize telemetry that supports correlation across channels and time. Invest in sequence modeling for workflows that matter in terms of criticality (e.g., support recovery paths, entitlement changes, admin role grants, data export flows). Ensure high-risk actions emit rich audit events with consistent schemas. Treat support tooling as part of your security surface, not a back-office function. Introduce step-up checks that are specifically designed to degrade orchestration efficiency: controls that become more stringent when the system detects phased exploration, not only when it detects an obvious exploit signature.
And maybe most importantly, measure the right thing. Per-agent safety metrics won’t capture this class of risk. You need operational metrics: how quickly do you detect a coordinated probe? How quickly can you raise marginal cost for the operation? How often do you force the adversary to pivot? How often do you degrade the operation without materially harming legitimate users?
Mature fraud programs track metrics like the ones above. Agent swarms are a good reason to import them into AI security programs.